 muziyoshiz.jpまでどうぞ。
muziyoshiz.jpまでどうぞ。
2005/06/07
■[年表][SBM]年表ウェブ(Chronologic Web)の構成要素
※繋がりの多様性を特徴とする「ソーシャル年表サービス」の提案(2005/05/24)の続きです。
前回の日記では「ソーシャル年表サービス」のコンセプトに関する話に終始していましたが、今回からはこのサービスをどうすれば実装できるかを考えてみます。
ちなみに、「ソーシャル年表サービス」という名前は少し長いし語呂が悪いので、今回からは「年表ウェブ(Chronologic Web)」という名前で呼ぶことにしました(Semantic Webと語感を似せたかったので、chronologicalじゃなくてchronologic)。
で、今回はまず以下の要求からスタートして、年表ウェブの構成要素について考察してみます。
■ 要求:良い年表データはいつまでも残したい
前回の日記では、年表ウェブは「扱うデータ(出来事)に日付の情報を組み込んでいるため、時間経過の影響を受けにくい」メリットがあるという話をしましたが、そのメリットを活かすためには、まず年表データ自体が時間経過によって消えない(=いつまでも残せる)必要があります。
つまり、良い年表はその作成者が居なくなったとしても、それを支持する人によって残される。そういう仕組みが年表ウェブには要求されます*1。
そう考えると、年表ウェブを実現するための機能は特定のノードに集中させずに、出来るだけ複数のノードに分散して余裕を持たせるのがよさそうです(特定のノードに集中させると、そのノードがダウンしただけでサービス全体が使えなくなってしまう)。そこで、次はこの年表ウェブを実現するための構成要素について考えてみます。
■ 構成要素
年表ウェブの構成要素は、各機能毎に以下の5つに分けることができます。これらは、いくつかまとめて1つのノードに実装することも、全て別のノードに実装することもできます。
- Repository(保管)
- Certifier(証明)
- Aggregator(集約)
- Viewer(閲覧)
- Creator(作成)
まず、Repositoryは、年表データ(年表、出来事など)を保管し、提供する機能をもつ構成要素です。ユーザがCreatorを通して作成した年表データは、このRepositoryが保管します。また、閲覧するユーザがAggregatorを通して検索条件をRepositoryに渡すと、Repositoryはその条件を満たす年表データを返します(このインタフェイスの詳細は後日まとめます)。
次に、Certifierは、年表データの作成者が誰かを証明するためのデータ(ユーザデータ)を管理する機能を持つ構成要素です。Certifierは年表データを作成するユーザの認証を行います。また、年表データの完全性などもこれが提供します。
Aggregatorは、複数の年表データを集約する機能を持つ構成要素です。年表ウェブから複数の年表、出来事をかき集めて、ユーザの指示に従ってそれらを整形する、RSSリーダ(アグリゲータ)のような役割を果たします。年表ウェブの検索エンジンを作るとしたら、それはアグリゲータの一種になります。
Viewerは、Aggregatorが集約した年表データを閲覧する機能を持つ構成要素です。AggregatorがCGIとして提供される場合は、ViewerはWebブラウザに相当し、Aggregatorがデスクトップ上で動作するソフトウェアとして提供される場合は、Viewerと一体になります。やっぱりRSSリーダに似ていますね。
最後に、Creatorは、年表データを作成し、それをRepositoryに登録する機能を持つ構成要素です。Creatorは、年表データを作成または登録する際に認証情報を扱う必要があります(後述)。
ここまでが、機能の分散を考えるための前準備です。
■ サーバからP2Pネットワークへの移行
で、ここからは、上記の構成要素が、どうやって複数のノードに分散されていくかを、図を見ながら説明していきます。ただ、Creatorは常にユーザに最も近いノードに配置されるため、以下の図では省略しました。
※ちょっと余談になりますけど、実際に年表ウェブを実装するとしたら、最初はC/S(クライアント/サーバ)型の実装でスモールスタートして、徐々にP2P型のネットワークに軸足を移していくのが良いと僕は思っています。その場合も、おおよそ以下の順に移行を進めることになりそうです。
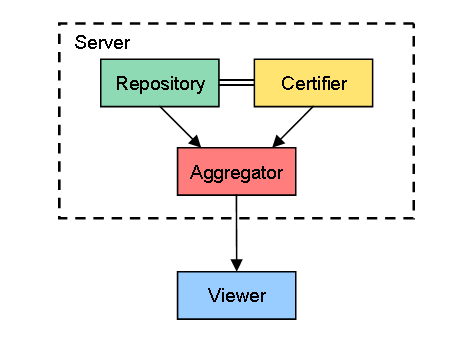
1. データを1つの固定サーバに集中
一番単純なのは、下の図のようにRepository、CertifierそしてAggregatorの機能を1つの固定サーバに集中させるケースです。矢印はデータ(年表データ、ユーザデータ)の流れを表し、二重線は年表データとユーザデータの関連付けを表しています。
現時点で各社から提供されているソーシャルブックマークは、全てこのケースですね。
 (クリックして拡大)
(クリックして拡大)
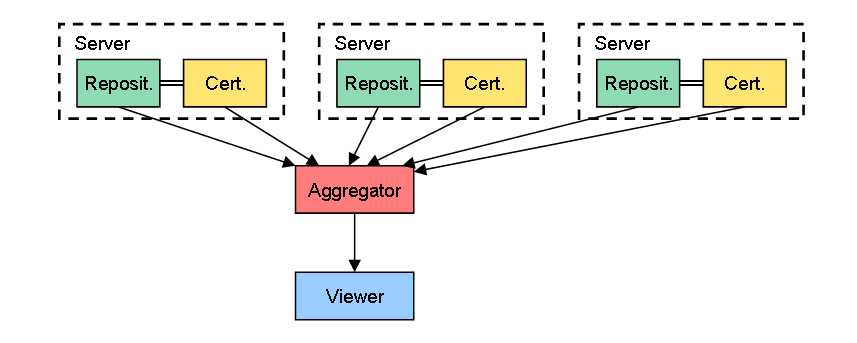
2. データを複数の固定サーバに分散
次に考えられるのが、RepositoryとCertifierのセットを、複数の固定サーバに分散するケースです。これは、現在のWebサーバ、検索エンジン、Webブラウザとちょうど同じような関係になります。
 (クリックして拡大)
(クリックして拡大)
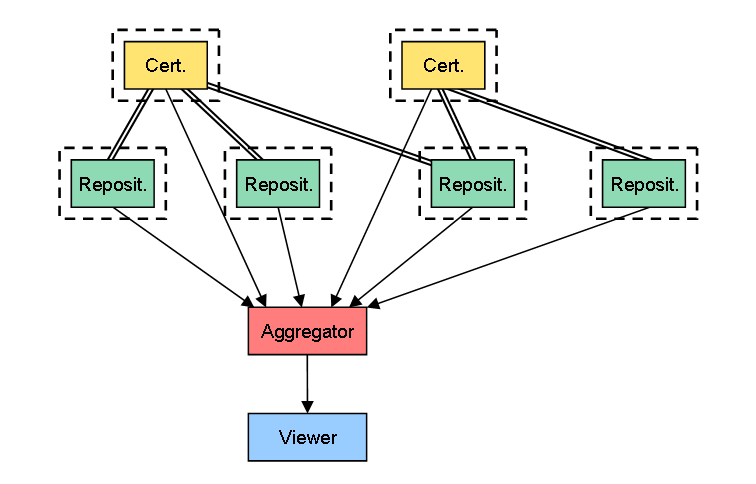
3. RepositoryとCertifierの機能を、異なる固定サーバに分散
これは、RepositoryとCertifierの機能を異なるサーバに分離し、それに加えて1つのCertifierが複数のRepository(正確にはその上の年表データ)をまかなえるようになるケースです。こっちは、TypeKeyのサーバと、無数に存在するMovable Typeの関係に近いですかね。
具体的には、以下のような実装を考えています。
- Creatorは年表データ作成のための公開鍵と秘密鍵を作成し、Certifierからその公開鍵の証明書を発行してもらう(Certifier=CA)
- 証明書はRepository上に保管する
- Creatorは年表データの作成時に、上記の秘密鍵で署名する
- Aggregatorは年表データを集約する際に、その署名が正しいかどうか検証する
 (クリックして拡大)
(クリックして拡大)
4. Repositoryの機能を、動的に構成されるネットワーク上に分散
ここからP2Pネットワークの登場です。これは、Repositoryの機能を、常時起動していることが保証されている固定サーバに持たせるのではなく、出入りのあるノード(ピア)によって動的に形成されるネットワークに持たせるケースです。
P2P掲示板を実現する方法や、DHT(分散ハッシュテーブル)を使えば実現できそうな気がします。P2P勉強会で講演したことあるような人に聞いてみたら、具体的にどうすればいいか分かるかも……。
このケースでは、まだCertifierの機能を固定サーバに頼っています。その意味では、ログイン時(認証あり)のみ固定サーバにアクセスし、それ以降はスーパーノードに接続する、という動作を行う現在のSkypeに似た構成とも言えます。
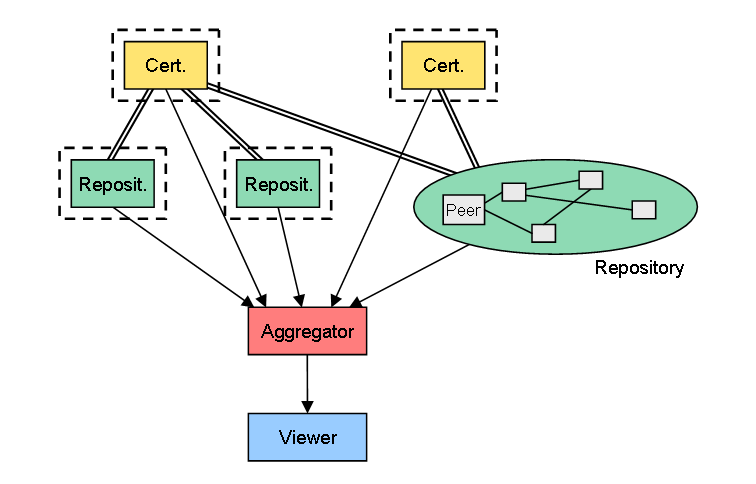 (クリックして拡大)
(クリックして拡大)
5. Certifierの機能を、動的に構成されるネットワーク上に分散
そして最後は、Certifierの機能までも、固定サーバからP2Pネットワークへと移行させたケースです。ここでは、PGPに代表されるような、証明書配布のための評判システムが重要になります。
ここまでする必要があるかどうかはともかくとして、ちょっと面白そうですね。
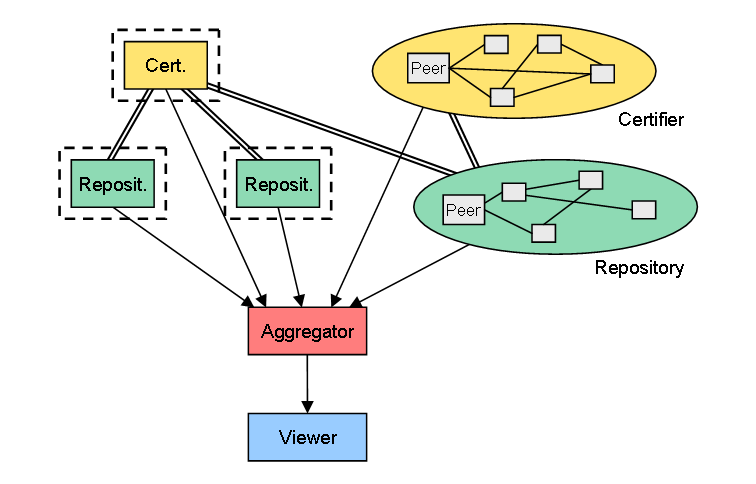 (クリックして拡大)
(クリックして拡大)
■ まとめ
年表は、長い年月を経た後にこそ価値があります。それは、例えば最近発売された教科書には載らないニッポンのインターネットの歴史教科書を見るとよく分かります(僕も買いました&だいぶ影響されてます)。
そこで、年表を後々まで残すためには、年表ウェブを実現するための機能を特定のノードに集中させず、出来るだけ複数のノードに分散できることが重要になります。今回は、1つの固定ノードから複数の固定ノードへの分散、更に固定ノードから出入りのあるノード(ピア)への分散まで考えてみました。
次回はより具体的な実装の話――例えば、Repositoryのインタフェイス、Repositoryと分離したIDの決定方法、正しい利用と不正利用の切り分け、匿名性の扱い、等――の中から何かテーマを選んで書いてみます。
ところで。
現在、国内のソーシャルブックマークは「はてなブックマーク」が主流になりつつありますけど、今回の検討内容と同じような形でソーシャルブックマークも分散化できると思います。……誰かやってみませんか?
*1 これはライセンスの問題と密接に絡むのですが、そのあたりはまだちゃんと検討しきれてないので省略します。うーん……。
[ツッコミを入れる]
2005/06/13
■[SBM][SNS]コミュニティとタグの関連付け(SNS+SBMについて再考)
※Rojo / ソーシャルブックマークとソーシャルネットワークの微妙な関係(2005/04/26)に送られたトラックバックへの反応です。
以前、ソーシャルブックマークとソーシャルネットワークを組み合わせたRojoというサービスを日記(2005/04/26)で取り上げました。この日記の後半で、ソーシャルネットワーク上の情報をブックマークの表示順位に反映させるといいのでは?という話を書いたのですが、それに対して以下のトラックバックをいただきましたのでご紹介します。
SBM+SNSの最有力はコミュニティ、と思う。(kokepiの日記)
http://d.hatena.ne.jp/kokepi/20050527/1117182974
URLをハテナブックマークする時に、参加してるmixiコミュニティのうち、関連しそうなものを関連付けられるようにする。
で、次のように評価する。
◆評価
- 無関係の人のブックマーク:普通
- 無関係の複数の人のブックマーク:重要(コミュニティには関係ない)
- 同じコミュニティの参加者がブックマーク:普通
- 同じコミュニティの参加者がコミュニティに関連付けしたブックマーク:コミュニティにとって重要
- 同じコミュニティの複数の参加者がコミュニティに関連付けしたブックマーク:コミュニティにとって超重要
つまり、「SNS(mixi)のコミュニティ毎にブックマークを重要度評価したらどうか」というアイディアです。確かに、なんとなくうまくいきそうな気がします。
ただ、その一方でちょっと良く分からないところもあったので、また例のごとくゴチャゴチャと図を描きながら考えてみました。それが以下の図です。赤い矢印と線は、ユーザがWebサイトをブックマークすると同時に、そのWebサイトを特定のコミュニティに関連付けている様子を示しています。
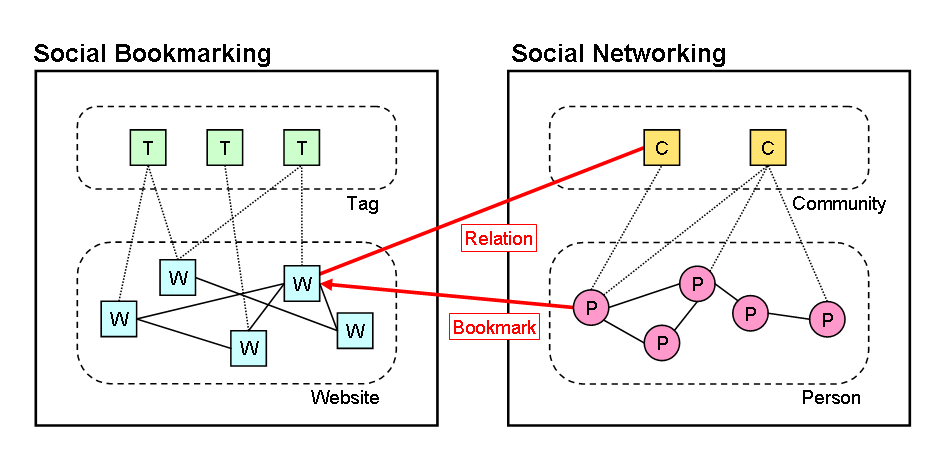 (クリックして拡大)
(クリックして拡大)
で、こうやって描いてみて、これは何か非効率な気がしてきました。タグを付けて、更にコミュニティと関連付けるのは、二度手間というか、SBMが2個あるのと変わらないというか……。はてなブックマークなどのSBMには元々タグ(タグをキーワードに置き換えても可)があるので、コミュニティとブックマークを関連付けるんじゃなくて、
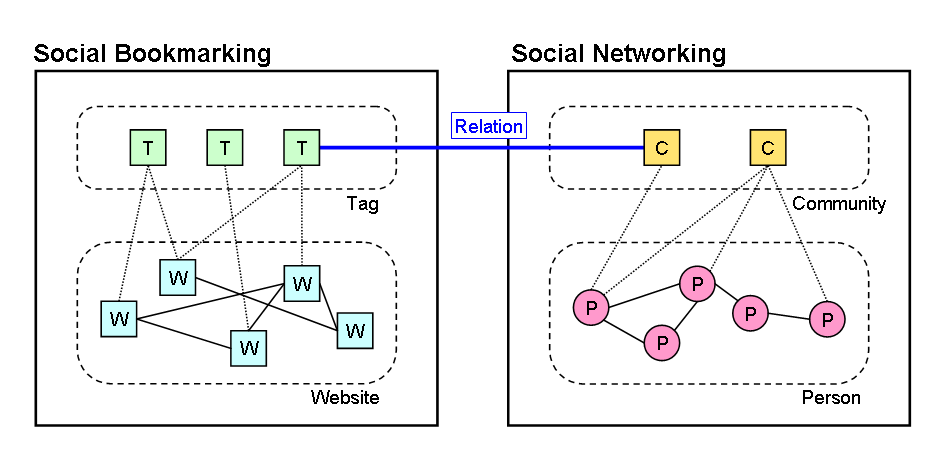 (クリックして拡大)
(クリックして拡大)
こうやって、コミュニティとタグの関連付けをメンテできるようにした方が、効率は良さそうです。ただ、どういう方法でメンテしたらいいのか、と言われると……具体案はまだ全然ないですけど。
----
ところで、既にdel.icio.usやはてなブックマークを使い込んでいる人は、上記の話を見て
「タグを指定してブックマークを表示する機能が既にあるんだから、わざわざコミュニティとタグを関連付ける必要なんてないのでは?」
という疑問が沸いたかもしれません。
確かに、実用的にはそうかもしれない、と僕も思うんですけど……もしも上記の関連付けを実現できるうまい方法が見つかれば、コミュニティ毎にカスタマイズされたニュースサイトを自動的に作ることが可能になります。
それもちょっと面白そうな気がするんですけど、どうでしょうか。
[ツッコミを入れる]
2005/06/21
■[SBM][SNS]はてなブックマーク+はてなグループ≒SBM+SNS(SBM+SNS話の続き)
※6月13日の日記への反応への反応です(反応遅くてすいません……って反応反応言い過ぎ)。
前回の日記に対して、kokepiさんから更にトラックバックをいただきました。キーワード(タグ)だけではコンテキストとして不足なのでは?という指摘です。
コミュニティとタグとブックマークの相互関連付け(kokepiの日記)
http://d.hatena.ne.jp/kokepi/20050616/1118923383
自分が「同じコミュニティに参加している人(特定の情報への強い関心が一致してる人)に絞って情報共有したい」と思うのは、コンテキストを重視して情報共有したい、という欲求なんだという気がしてきた。
キーワードだけじゃなくて、コンテキストで共有された新着やhotなURL情報を収集していきたい。しかも別々だと効率悪いので、ブックマークのインターフェイスにそれを統合してしまいたい。
また、それを受けてGadaraさんが「はてなグループとはてなブックマークの関連付け」というアイディアを提案していました。
複数アカウントがもたらすもの。そして……。(Gadara∵Diary)
http://d.hatena.ne.jp/gadaraorg/20050616/1118939962
俺はこの話を往復エントリーを読んで、はてなグループとはてなブックマークの関連付けを考えた。
http://www.html-mail.jp/images/rss_market/uri_tag_community_person.jpg
はてなグループは厳密にはSNSとは言えないと思うが、上の画像の構造をはてななら意外に簡単に実現できそうな気がするのだ。
はてなブックマークのタグやカテゴリの他に、その人が所属するグループを選択できるプルダウンメニューを用意することで、グループ毎にブックマークを作れるようにするのである。
(趣味のグループのニュース速報みたいなものになるのかな?)
こうなると、はてなグループのコミュニティ性が増すと思う。
確かに、SBMとSNSを提供しているところが一緒(ユーザ認証が一緒)なら、コミュニティ自体をタグとして扱ってしまえば話はだいぶ単純になりそうです*1。僕はずっとはてなブックマークとmixiの組み合わせで考えていたので、SBMとSNSは分離していることを前提にしてたんですけど、確かにはてなグループはSNS(のコミュニティ機能)みたいなもんですねえ。
そういえば、数日前のはてなダイアリー日記でこんな告知がありました。
はてなグループを利用した閲覧許可グループ、編集許可グループの設定機能について(はてなダイアリー日記)
http://d.hatena.ne.jp/hatenadiary/20050620/1119245318
本日、はてなグループを利用した閲覧許可グループ、編集許可グループの設定機能を追加しました。
好きなユーザーと趣味や興味、仕事などの共通項でグループが作れるはてなグループ(http://g.hatena.ne.jp/)で、自分が所属しているグループのメンバーに閲覧を許可したり、編集を許可したりすることができるようになりました。
この機能の延長で、自分がそのグループに所属しているかどうかで
- タグの付与:グループをタグとして使うこと
- タグに基づく検索:グループに対応したタグをキーにしてブックマークを検索、表示すること
といったタグ関連の動作が許可または禁止されるようにしたら面白いかもしれません。つまり、自分がどのグループ(コミュニティ)に所属しているかという情報をタグの利用制限(パーミッション制御)に使う、というわけです。
----
個人的にこういうサービスの囲い込みは好きじゃないんですけど、はてなは自社サービスを組み合わせることで想像以上に多様なサービスを提供できるのかもしれないですね……。はてなの恐ろしさを垣間見たような気がします。
*1 コミュニティを特別な名前空間のタグとして扱うような感じでしょうか。
[ツッコミを入れる]
2005/06/24
■[年表][P2P]年表ウェブ:年表データのポータビリティ(サーバとP2Pネットワークを行ったり来たり)
※年表ウェブ(Chronologic Web)の構成要素(2005/06/07)の続きです。
以前の日記でまとめた年表ウェブの構成要素の話を踏まえて、今回は年表データの流通について考えてみます。
今回の主張は以下の2点です。
- 良い年表を長く残すために、年表データは固定サーバと動的なP2Pネットワークの間を移動できた方が良い
- 動的なP2Pネットワークだけで年表ウェブを構成するよりも、固定サーバと併用した方がメリットが多い
■ サーバ型RepositoryとP2P型Repositoryの共存
年表ウェブでは、Repositoryという構成要素が、年表や出来事などの年表データを保管し提供する機能を持ちます(過去の日記を参照)。Repositoryは、以下の2通りの方法で実装することができます。
- サーバ型Repository:常時起動していることが保証されている固定サーバがRepositoryの機能を提供する
- P2P型Repository:出入りのあるノード(ピア)によって動的に形成されるP2Pネットワークが、仮想的な1つのサーバのように*1Repositoryの機能を提供する
(以前にも図で示した内容ですけど、今回は説明のため、それぞれの実装形態に名前を付けました。)
で、前回もチラッと書きましたけど、もし僕が年表ウェブと実装するとしたら、最初はサーバ型の実装でスモールスタートしてから、徐々にP2P型のネットワークに軸足を移していくのが良いと思っています。ただし、全ての機能をP2Pネットワークに移すのではなくて、最終的には下図のように、サーバ型のRepository/CertifierとP2P型のRepository/Certifierが共存する形が良いと思っています。
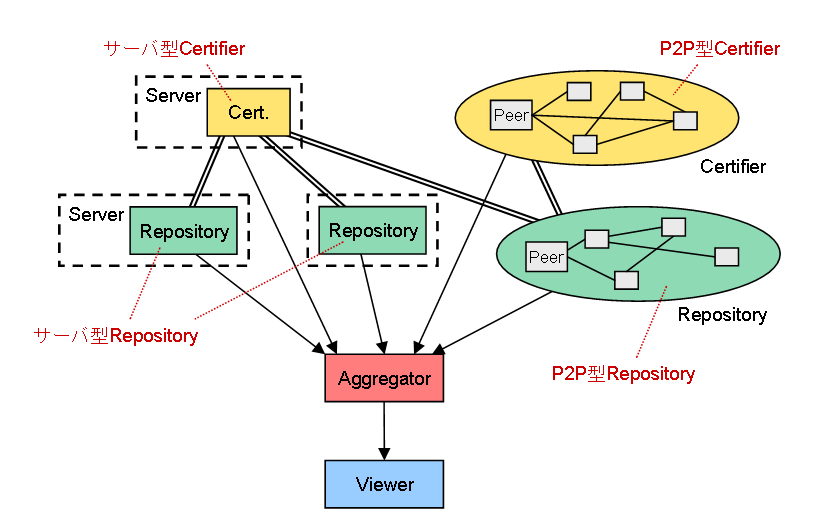 (クリックして拡大)
(クリックして拡大)
で、上記のようなネットワークの上で、ユーザの作った年表データが
- ユーザがCreatorで年表データを作る(このユーザを作者=Authorと呼ぶ)
- 作者は自分のサーバ型Repositoryで年表データを公開する
作者以外のユーザも、気に入った年表データは自分のサーバ型Repositoryで公開できる
- これは、年表データが二次配布可能なライセンス(Creative Commons等)に準拠することで実現可能
- 作者のRepositoryが何らかの理由で閉鎖しても、良い年表データは失われない
またユーザは、サーバ型Repositoryに限らず、P2P型Repositoryでも年表データを公開できる
- サーバ型Repositoryを持たない(そこまでの手間を払いたくない)ユーザでも、気に入った年表データの流通プロセスに関われる
- 更に、P2P型Repository上で見つけた年表データを、再びサーバ型Repositoryに移すこともできる
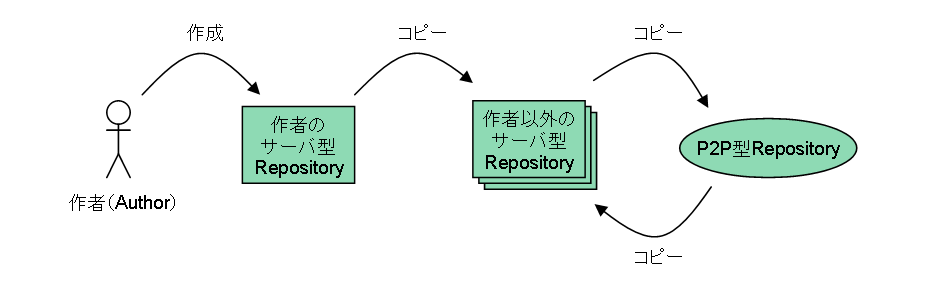 (クリックして拡大)
(クリックして拡大)
という感じで流通できるようにするのが、今のところ僕が頭に描いている理想像です。
■ サーバ型Repositoryのメリット
と、こういう話をすると、ここをP2P関連サイトとしてチェックされている方からは「別に全部P2P型でもいいんじゃね?」と突っ込まれそうな気がします。が、一応、以下のような点がメリットになると思っています。
1. blog等、既存Webアプリとの連携
Webサーバとサーバ型Repositoryが同じ固定サーバ上で動作していれば、両者間での連携はいろいろと考えられます。
例えばWebサーバ上でblogを公開している場合、blogツールでエントリを書くのと同時に、そのエントリに関連する出来事(当然、関連サイトとしてそのエントリのURLを含む。年表ウェブの提案(2005/05/24)を参照)をRepositoryに登録できるようにする、と便利そうです。
また、blogのエントリ表示時に自分が作成した(または拾ってきた)年表データを利用して、そのエントリが書かれた前後の出来事も一緒に表示できるようにする*2、といった二次利用の方法も考えられます。
2. 責任範囲の明確化
少し話がズレるのですが、P2P BBSのような既存のP2Pアプリでは、「P2Pネットワーク上のコンテンツへアクセスするためのゲートウェイとして動作するHTTPサーバ」を固定サーバ上で運用することがあります。
そのような形でも、同じサーバ上でWebアプリとP2Pネットワーク(この場合はP2P型Repository)へのゲートウェイを動作させれば上記1.のような連携は可能になるのですが、このようなゲートウェイは、いつの間にかユーザの望まないコンテンツの公開に荷担してしまう可能性があります。
一方、サーバ型Repositoryでは自分が明示的に追加しない限りデータが増えることはありません(年表の継承は、元データの修正ではない)。つまり、BitTorrentのように合法利用と不正利用の世界を明確に切り分けられます。まあ、BitTorrentはかなり盛大に不正利用されているみたいですけど……それでもWinnyのように合法利用と不正利用が完全に混在してしまうものよりは合法利用しやすい、ということはありそうです。
3. サービスの継続性
以前、あるP2Pアプリケーションを利用していたときに、そのアプリが形成するネットワークが悪意あるユーザから攻撃を受けて、サービス全体が長期に渡って利用できなくなる、という出来事がありました。
もちろん、そのようなサービス妨害(DoS攻撃)に強いP2Pアプリケーションを作ることは可能だと思いますが、いきなり完全な仕組みを作れるはずもなく、完成までには何度も攻撃を受けるはずです。いや、むしろDoS攻撃への完全な対策なんてあり得ず、いつまでも悪意あるユーザとのいたちごっこが続く可能性さえあります。
しかし、サーバ型Repositoryだけでも使えるようにしておけば、年表ウェブのサービスはP2P型Repositoryが使えなくなっても、(これはおかしな話に聞こえるかもしれませんが)草の根で生き延びることができます。
----
少し長くなりそうなので、今日はここまで。次回はこのような年表のポータビリティを実現するための要求条件について考えてみます。
[ツッコミを入れる]
2005/06/27
■[P2P]DHTオフ会に参加してきました
昨日は、Tomo's HotlineのTomoさん主催のDHTオフ会に参加してきました。会場は筑波大学(東京からバスで1時間強)。ホント、皆さんお疲れ様でした……。
イベントの概要と、反応リンク集はこちら(↓)。
[DHT]DHTオフ会参加者募集について(Tomo's HotLine)
http://toremoro.tea-nifty.com/tomos_hotline/2005/05/dhtdht_57f1.html
DHTオフ会 リンク集(P2P today ダブルスラッシュ)
http://wslash.com/?itemid=208
最初の小島さんの講演では、Small World NetworkやScale-Free Networkを含むComplex Networkと、DHT技術の関連性について解説されました。その後1人1分程度の自己紹介タイムを挟んで、Tomoさんの講演では、DHTを利用したさまざまな応用アプリのアイディアが紹介されました。議論の時間も長く取られ、なかなか盛り上がって良い感じでしたね。あっという間の4時間半でした。
個人的には、今回のイベントでようやくComplex NetworkとDHTの話の関連性が分かったような気がします。最近、知り合いに「スケールフリーのDHTってあるの?」って聞かれて返事に窮してしまったことがあるんですけど、今後はなんとか
「えーと、DHTはスモールワールドなんだけど、DHTのネットワークを階層化することでスケールフリーの長所を取り入れることも出来る……という感じ?」
とかごまかせそうです(ごまかせてない)。
(小島さんのプレゼン資料も後日公開*1されるらしいので、またそれ読んで勉強します)
----
しかし噂には聞いてましたけど、筑波大学はほんとにだだっ広いところでした。キャンパス内に池とかあるし(写真)。


でも実際に行って見てみると、この雰囲気はなかなか良いもんですね。こういうところで大学生活したかったなぁ……。
*1 2005/06/28追記:プレゼン資料が公開されました。小島さんのサイト→DHTオフ会資料(地平線を越えて)
[ツッコミを入れる]
スパム対策のため、60日以上前の日記へのコメント及びトラックバックは管理者が確認後に表示します。
また、この日記に無関係と判断したコメント及びトラックバックは削除する可能性があります。ご了承ください。
また、この日記に無関係と判断したコメント及びトラックバックは削除する可能性があります。ご了承ください。


{kind=link}